Metrics for evaluating classification models
While looking at top image classification models, we discussed popular evaluation metrics for classification. In this post, let’s explore different model metrics further.
Model complexity metrics
If you’re interested in improving model efficiency, you should keep an eye on metrics like model parameters and FLOPs
Parameters
Parameters are internal variables that machine learning models adjust during their training process to improve their ability to make accurate predictions. The size of a model, in terms of parameters, directly influences its complexity, capacity and resource requirements (memory and computation). In previous post I added models parameters for each model where applicable: Top models for image classification.
Don’t confuse with hyperparameters. While parameter are adjusted during model training, hyperparameters are external configurations that data scientists manually set before training a model. Examples of hyperparameters include the number of nodes and layers in a neural network, learning rate and number of iterations.
Layers
In deep learning, a layer is a fundamental building block of a neural network. It consists of a set of neurons (or nodes) that perform a specific operation on the input data and pass the result to the next layer. Neural networks are typically composed of multiple layers stacked together, hence the term “deep” in deep learning, which refers to the depth of the network.
| Dense layer | Also called the fully-connected layer. In this layer, neurons connect to every neuron in the preceding layer |
|---|---|
| Convolutional layer | Typically used for image analysis tasks. In this layer, the network detects edges, textures and patterns |
| Pooling layer | Used to reduce the size of the data input |
| Attention layer | Allows the model to focus on specific parts of the input when making decisions |
| Normalization layer | Adjusts the input data from previous layers to achieve a regular distribution |
FLOPs
FLOPs (Floating point operations) are commonly used to calculate the computational complexity of a model. FLOPs refer to the number of floating-point operations (such subtraction, multiplication, and division) performed during training. By optimizing this metric, we can potentially reduce the time taken to train or run a neural network, as well as power consumption of the hardware on which the neural network is running. For example, in EfficientNet the smallest model, EffiecientNet-B0 has 0.39B FLOPs, while the largest EfficientNet-B7, has 37B FLOPs.
According to EU AI Act general purpose AI models that were trained using a total computing power of more than 10^25 FLOPs are considered to pose systemic risks. At the same time, GPT-4 pre-training required about , and Llama 3 400B estimated FLOPs are
Don’t confuse with FLOPS (Floating point operations per second) which measure a computer’s performance - the higher the FLOPS, the quicker the device. For example, NVIDIA GeForce RTX 3060 Ti performance for FP16 (16-bit floating point), FP32 (32-bit floating point) and FP64 (64-bit floating point) precision is shown below:
| FP16 (half) | 16.20 TFLOPS (1:1) |
|---|---|
| FP32 (float) | 16.20 TFLOPS |
| FP64 (double) | 253.1 GFLOPS (1:64) |
Object detection and classification metrics
YOLOv8 main task is object detection. In object detection, just like in classification, a model can predict a positive class or negative class, and the predictions can be true or false. For example, when detecting the presence of cats in an image, the positive class may be “Cat”, while the negative class would be “No cat”. A true prediction occurs when the prediction is correct, and a false prediction occurs when the prediction is incorrect. Therefore, we can have 4 different prediction outcomes:
| True positive (TP) | The model predicted that there is a cat, and it is correct |
|---|---|
| False positive (FP) | The model predicted that there is a cat, and it is incorrect |
| False negative (FN) | The model predicted that there is no cat, and it is incorrect |
| True negative (TN) | The model predicted that there is no cat, and it is correct |
Key metrics in object detection include precision, recall, intersection over union (IoU) and average precision (AP). All of them except IoU can be used in classification tasks.
Precision
Precision tells you how many of the detected objects are actually correct. In other words, it is the ratio of the number of true positives to the total number of positive prediction. For example, if the model detected 5 cats and 4 were correct, the precision is 0.8
Recall
Recall measures how many of the actual objects were successfully detected. In other words, it is the ratio of the number of true positives to the total number of actual positives. For example, if the model correctly detects 3 cats and there are actually 5 cats in the image, the recall is 0.6
F1 score
The F1 score is a weighted average of the precision and recall. The values range from 0 to 1, where 1 indicates the highest accuracy.
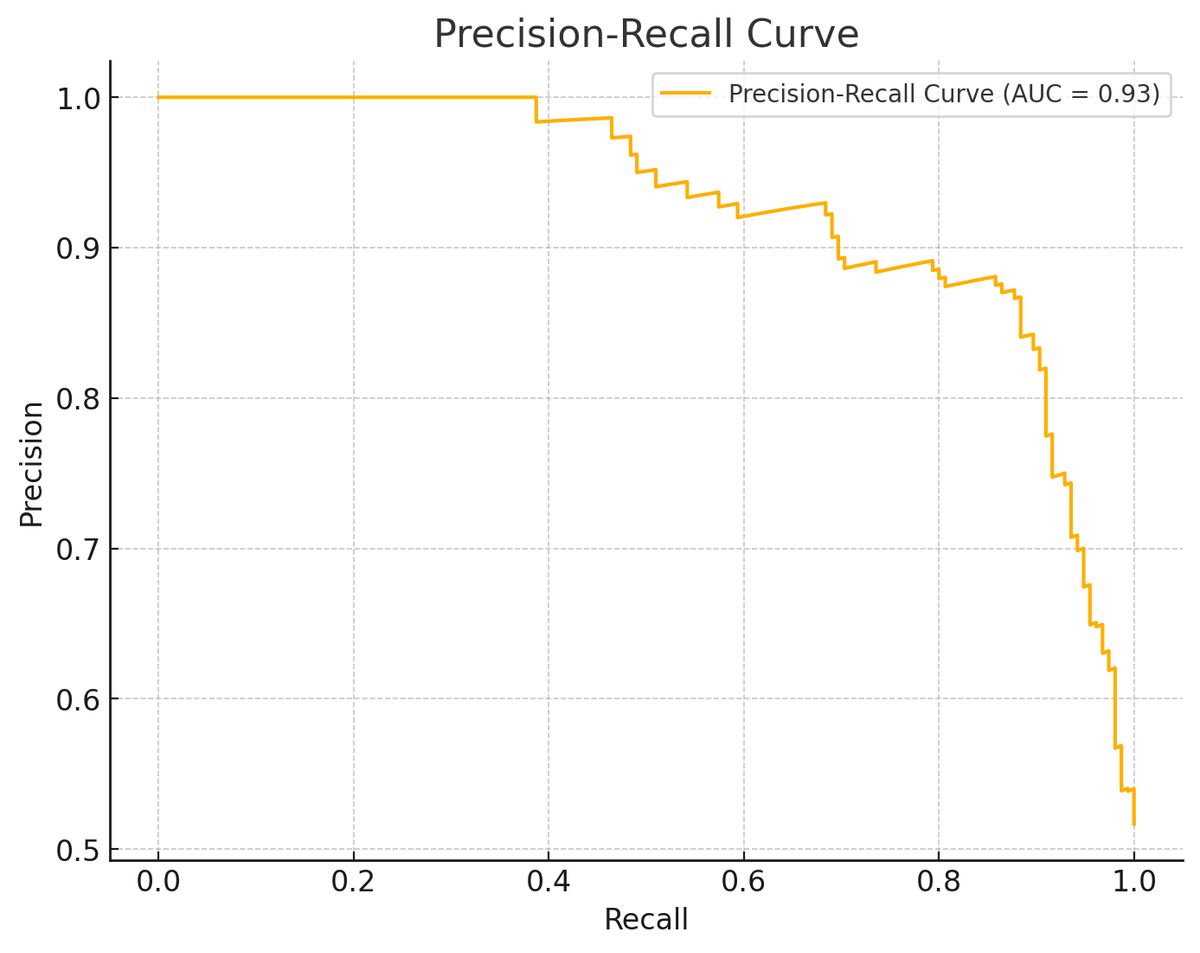
Precision-recall curve
Precision-recall curve is a plot of precision (y-axis) and recall (x-axis), shows the trade-off between precision and recall at different classification thresholds. A model is considered good if the precision stays high as the recall increases.
Precision-recall AUC
Area under the precision recall curve (AUC) is calculated by numerically integrating the precision-recall curve, giving a single value that summarizes the curve’s overall shape.
Average precision (AP)
Average precision combines precision and recall into a single score, offering a comprehensive view of model performance. It computes the weighted mean of precision at each threshold where recall changes. AUC is often used by machine learning researchers, while AP is more common in the information retrieval community.
Mean average precision (mAP)
Mean Average Precision (mAP) is a common evaluation metric used in tasks like multi-label classification and object detection. For example, the OmniVec model achieves 0.548 mAP in Audio Classification benchmark on AudioSet. a dataset of over 2M human-annotated 1- second video clips. AudioSet uses a hierarchical ontology of 632 event classes, meaning that the same sound could be annotated as different labels. For example, the sound of barking is annotated as Animal, Pets, and Dog. After calculating AP for each class in, the mean of these AP values across all classes gives the mAP.
Mean accuracy
The metric is typically applied when a model is evaluated across multiple tasks. For example, ViT was evaluated on the 19-task VTAB classification suite. VTAB evaluates low-data transfer to diverse tasks, using 1 000 training examples per task. The tasks are divided into three groups: Natural (7 tasks), Specialized (4 tasks), and Structured (8 tasks).
Intersection over union (IoU)
IoU calculates the overlap between predicted and ground truth bounding boxes, which is crucial for assessing detection accuracy. IoU ratio is used as a threshold for determining whether a predicted outcome is a true positive or a false positive
Loss
Lastly, loss is a metric that measures how well the model’s predictions match the true labels during training. Loss functions guide the model in improving its predictions by adjusting the model’s parameters through techniques like backpropagation and gradient descent. For classification, a commonly used loss function is cross-entropy loss.
Conclusion
Understanding key metrics in object detection and classification is crucial for evaluating model performance and optimizing results. Metrics like precision, recall, and F1 score offer insights into the accuracy and balance of predictions, while more advanced metrics such as IoU and mAP are essential for complex tasks like object detection. Each metric serves a unique purpose, helping us analyze different aspects of model behavior, whether it’s detecting objects in images or classifying them into correct categories. By applying the right metrics and interpreting the results effectively, you can make informed decisions to improve model performance, ensuring that your solutions are both accurate and efficient.